MySQL写压力性能监控与调优
一、关于DB的写
1、数据库是一个写频繁的系统
2、后台写、写缓存
3、commit需要写入
4、写缓存失效或者写满–>写压力陡增–>写占读的带宽
1、BBU失效
2、写入突然增加、cache满
5、日志写入、脏缓冲区写入
二、写压力性能监控
全面剖析写压力:多维度的对写性能进行监控。
1、OS层面的监控:iostat -x
|
1 2 3 4 5 6 |
[root@localhostmydata]#iostat-x Linux2.6.32-642.el6.x86_64(localhost.chinaitsoft.com)07/05/2017_x86_64_(8CPU) avg-cpu:%user%nice%system%iowait%steal%idle0.000.000.030.000.0099.97 Device:rrqm/swrqm/sr/sw/srsec/swsec/savgrq-szavgqu-szawaitr_awaitw_awaitsvctm%util scd00.000.000.000.000.010.007.720.001.251.250.001.250.00sdc0.020.000.010.000.070.007.930.000.890.890.000.720.00sda0.180.130.130.055.381.4337.950.006.633.9913.772.230.04sdb0.030.000.010.000.120.008.720.001.140.8035.890.710.00 |
1、写入的吞吐量:wsec/s sec=512字节=0.5K、写入的响应时间:await
2、我们需要确认我们的系统是写入还是读取的系统,如果是写入为主的系统,写压力自然就大,相关状态值也就大些。
3、监控系统的io状况,主要查看%util、r/s、w/s,一般繁忙度在70%,每秒写也在理想值了;但如果系统目前繁忙度低,每秒写很低,可以增加写入。
2、DB层面监控,有没有写异常:监控各种pending(挂起)
|
1 |
mysql>showglobalstatuslike'%pend%';+------------------------------+-------+|Variable_name|Value|+------------------------------+-------+|Innodb_data_pending_fsyncs|0|#被挂起的fsync|Innodb_data_pending_reads|0|#被挂起的物理读|Innodb_data_pending_writes|0|#被挂起的写|Innodb_os_log_pending_fsyncs|0|#被挂起的日志fsync|Innodb_os_log_pending_writes|0|#被挂起的日志写+------------------------------+-------+5rowsinset(0.01sec) |
写挂起次数值大于0,甭管是什么写挂起,出现挂起的话就说明出现写压力,所以值最好的是保持为0。监控“挂起”状态值,出现大于0且持续增加,报警处理。
3、写入速度监控:日志写、脏页写
1、日志写入速度监控
|
1 |
mysql>showglobalstatuslike'%log%written';+-----------------------+-------+|Variable_name|Value|+-----------------------+-------+|Innodb_os_log_written|5120|+-----------------------+-------+1rowinset(0.01sec) |
2、脏页写入速度监控
|
1 |
mysql>showglobalstatuslike'%a%written';+----------------------------+---------+|Variable_name|Value|+----------------------------+---------+|Innodb_data_written|1073152|#目前为止写的总的数据量,单位字节|Innodb_dblwr_pages_written|7||Innodb_pages_written|58|#写数据页的数量+----------------------------+---------+3rowsinset(0.01sec) |
3、关注比值:Innodb_dblwr_pages_written /Innodb_dblwr_writes,表示一次写了多少页
|
1 |
mysql>showglobalstatuslike'%dblwr%';+----------------------------+-------+|Variable_name|Value|+----------------------------+-------+|Innodb_dblwr_pages_written|7|#已经写入到doublewritebuffer的页的数量|Innodb_dblwr_writes|3|#doublewrite写的次数+----------------------------+-------+2rowsinset(0.00sec) |
1、如果该比值是64:1,说明doublewrite每次都是满写,写的压力很大。
2、如果系统的double_write比较高的话,iostat看到的wrqm/s(每秒合并写的值)就高,因为double_write高意味着每次写基本上都是写2M,这时候就发生更多的合并,但wrqm/s高并不害怕,因为发生合并是好事,看wrqm/s和繁忙度能不能接受。
4、脏页的量监控
|
1 2 3 |
mysql>showglobalstatuslike'%dirty%';+--------------------------------+-------+|Variable_name|Value|+--------------------------------+-------+|Innodb_buffer_pool_pages_dirty|0|#当前bufferpool中脏页的数量|Innodb_buffer_pool_bytes_dirty|0|#当前bufferpool中脏页的总字节数+--------------------------------+-------+2rowsinset(0.01sec) mysql>showglobalstatuslike'i%total%';+--------------------------------+-------+|Variable_name|Value|+--------------------------------+-------+|Innodb_buffer_pool_pages_total|8192|#bufferpool中数据页总量+--------------------------------+-------+1rowinset(0.01sec) |
关注比值:Innodb_buffer_pool_pages_dirty /Innodb_buffer_pool_pages_total,脏页占比
通过比值看脏页是否多,比如脏页10%的话,可以判断系统可能不是写为主的系统。
5、写性能瓶颈
|
1 2 3 |
mysql>showglobalstatuslike'%t_free';+------------------------------+-------+|Variable_name|Value|+------------------------------+-------+|Innodb_buffer_pool_wait_free|0|+------------------------------+-------+1rowinset(0.01sec) mysql>showglobalstatuslike'%g_waits';+------------------+-------+|Variable_name|Value|+------------------+-------+|Innodb_log_waits|0|+------------------+-------+1rowinset(0.00sec) |
1、Innodb_buffer_pool_wait_free,如果该值大于0,说明buffer pool中已经没有可用页,等待后台往回刷脏页,腾出可用数据页,这样就很影响业务了,hang住。
2、Innodb_log_waits,如果该值大于0,说明写压力很大,出现了日志等待。
6、系统真实负载:rows增删改查、事务提交、事务回滚
|
1 2 3 4 5 |
mysql>showglobalstatuslike'i%rows%';+----------------------+-------+|Variable_name|Value|+----------------------+-------+|Innodb_rows_deleted|0||Innodb_rows_inserted|145||Innodb_rows_read|233||Innodb_rows_updated|5|+----------------------+-------+4rowsinset(0.01sec) mysql>showglobalstatuslike'%commit%';+----------------+-------+|Variable_name|Value|+----------------+-------+|Com_commit|0||Com_xa_commit|0||Handler_commit|16|+----------------+-------+3rowsinset(0.01sec) mysql>showglobalstatuslike'%rollback%';+----------------------------+-------+|Variable_name|Value|+----------------------------+-------+|Com_rollback|0||Com_rollback_to_savepoint|0||Com_xa_rollback|0||Handler_rollback|0||Handler_savepoint_rollback|0|+----------------------------+-------+5rowsinset(0.01sec) |
通过监控系统真实负载,如果业务正常,负载上升,写压力是那自然是无可厚非的。此时,就要根据业务具体情况,进行相应的调优。
三、写压力调优参数
降低写压力、加大写入的力度。
通过调整参数降低写压力时,一定要实时关注iostat系统的各项指标。
1、脏页刷新的频率
|
1 |
mysql>showvariableslike'i%depth%';+-----------------------+-------+|Variable_name|Value|+-----------------------+-------+|innodb_lru_scan_depth|1024|+-----------------------+-------+1rowinset(0.01sec) |
默认1024,遍历lru list刷新脏页,值越大,说明刷脏页频率越高。
2、磁盘刷新脏页的量:磁盘io能力
|
1 |
mysql>showvariableslike'%io_c%';+------------------------+-------+|Variable_name|Value|+------------------------+-------+|innodb_io_capacity|200||innodb_io_capacity_max|2000|+------------------------+-------+2rowsinset(0.00sec) |
根据磁盘io能力进行调整,值越大,每次刷脏页的量越大。
3、redolog调优
|
1 |
mysql>showvariableslike'innodb_log%';+-----------------------------+----------+|Variable_name|Value|+-----------------------------+----------+|innodb_log_buffer_size|16777216||innodb_log_checksums|ON|#解决数据在io环节的出错问题,checksum值检查|innodb_log_compressed_pages|ON||innodb_log_file_size|50331648||innodb_log_files_in_group|2||innodb_log_group_home_dir|./||innodb_log_write_ahead_size|8192|+-----------------------------+----------+7rowsinset(0.01sec) |
logfile大小和组数可能会导致写抖动:日志切换频率需要监控(文件系统层面技巧)。
4、redolog的刷新机制
|
1 |
mysql>showvariableslike'%flush%commit';+--------------------------------+-------+|Variable_name|Value|+--------------------------------+-------+|innodb_flush_log_at_trx_commit|1|+--------------------------------+-------+1rowinset(0.00sec) |
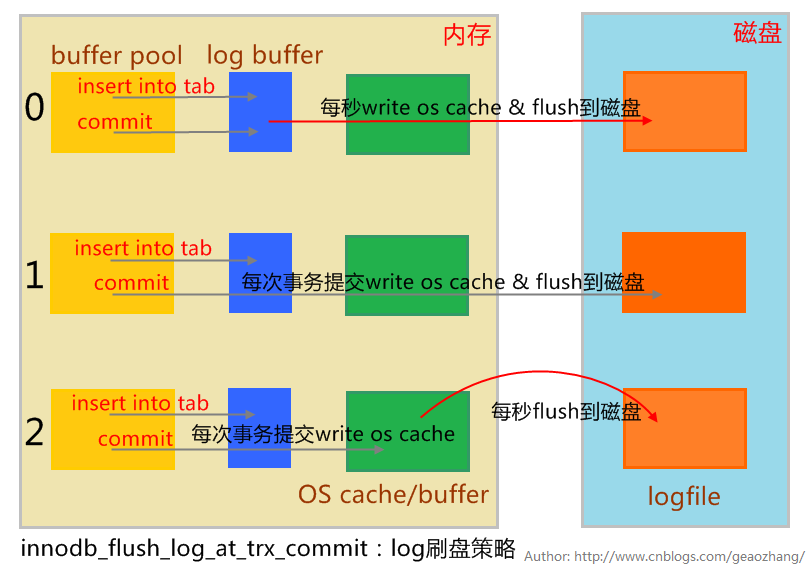
默认MySQL的刷盘策略是1,最安全的,但是安全的同时,自然也就会带来一定的性能压力。在写压力巨大的情况下,根据具体的业务场景,牺牲安全性的将其调为0或2。
关于redolog的刷盘策略:
也就是用户在commit,事务提交时,处理redolog的方式(0、1、2):
0:当提交事务时,并不将事务的redo log写入logfile中,而是等待master thread每秒的刷新redo log。(数据库崩溃丢失数据,丢一秒钟的事务)
1:执行commit时将redo log同步写到磁盘logfile中,即伴有fsync的调用(默认是1,保证不丢失事务)
2:在每个提交,日志缓冲被写到文件系统缓存,但不是写到磁盘的刷新(数据库宕机而操作系统及服务器并没有宕机,当恢复时能保证数据不丢失;但是文件系统(OS)崩溃会丢失数据)
5、定义每次日志刷新的时间
|
1 |
mysql>showvariableslike'innodb_flush_log_at_timeout';+-----------------------------+-------+|Variable_name|Value|+-----------------------------+-------+|innodb_flush_log_at_timeout|1|+-----------------------------+-------+1rowinset(0.01sec) |
默认是1,也就是每秒log